- Products & services Products & services
- Resources ResourcesCustomer resources
- Customer resources
- Customer support Find more information about engaging support and get help
- Services guide Find more information about working with Services teams
- Free resources Leverage our free tools and trainings
- Modernize to Identity Security Cloud Transition to the cloud for advanced capabilities and a future-ready security posture
Learning- Learning
- Identity University Get technical training to ensure a successful implementation
- SailPoint professional certifications & credentials Advance your career or validate your identity security knowledge
- SailPoint recertification program Get recertified by demonstrating ongoing learning
- Training onboarding guide Make of the most of training with our step-by-step guide
- Training FAQs Find answers to common training questions
- Community Community
- Compass
- :
- Discuss
- :
- Community Wiki
- :
- IdentityIQ Wiki
- :
- Pruning identity cubes
- Article History
- Subscribe to RSS Feed
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Content to Moderator
Pruning identity cubes
Pruning identity cubes
Introduction
When IdentityIQ reads an account from a connected application, it will try to correlate it to an existing identity cube and if that fails, create a new identity cube. When an account is removed from the source, IdentityIQ will also remove the account from the cube if the option to detect deleted accounts has been enabled on the aggregation task. If all accounts are removed from an identity cube, it will leave an "empty shell".
Other reasons for an identity cube to become empty are:
- All accounts are automatically re-correlated to another identity cube,
- An uncorrelated account is manually correlated to another identity cube,
- All accounts are manually moved to another or new identity,
- All accounts are remove through LCM,
- As part of the lifecycle, all accounts are disabled and later removed using lifecycle events and workflows.
These empty identity cubes most of the time do not serve any purpose and should be cleaned up. This is what the pruning feature in IdentityIQ is designed for.
The prune task
Out of the box, IdentityIQ comes with a task called "Prune Identity Cubes".
This task has four configuration options.
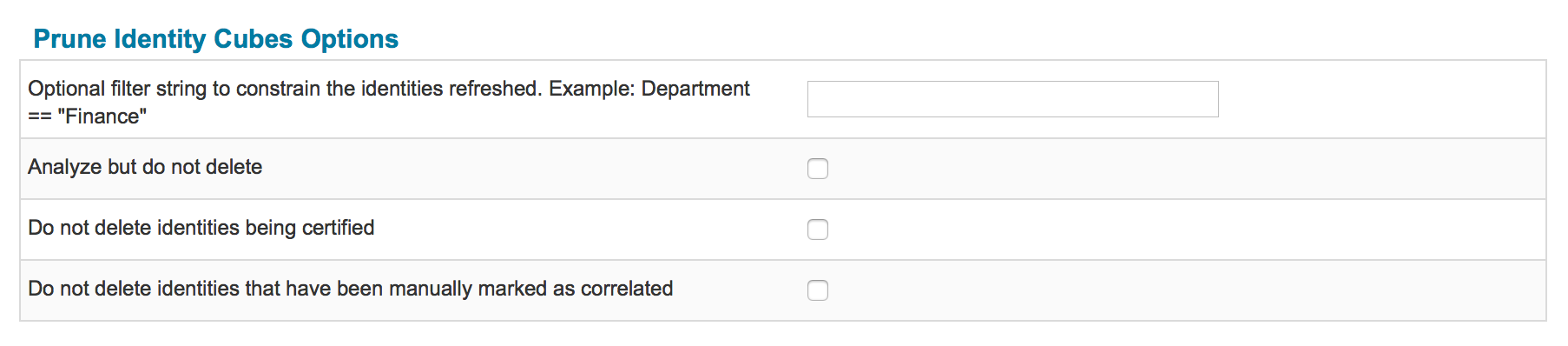
- The first option is similar to the filters that can be applied to the task Refresh Identity Cubes and derivatives of that task.
- The option Analyze but to not delete provides an option to perform a dry-run. If enabled, the task will only count the identities that would otherwise be deleted.
- If enabled the option Do not delete identities being certified prevents identities that are currently being reviewed as part of a certification (certification has not been completed) will not (yet) be deleted.
- If enabled the option Do not delete identities that have been manually marked as correlated prevents cubes that have been marked as manually correlated from being deleted.
Factors preventing pruning
First of all when the option Analyze but to not delete is enabled, it will not delete any identity. If that option is not enabled, it will process all identities, or those selected by the filter and evaluate whether or not to delete the identity cube. An Identity will not be deleted by the prune task if it:
- Has accounts in any connected application,
- Is a manager of other identities,
- Has any capability (set of SPRights), either directly or though a work group,
- Is manually correlated (and the option Do not delete identities that have been manually marked as correlated is ticked on the task),
- Has a “use by” date (e.g. set when creating an identity through the dashboard quicklink or self-registration),
- Is a direct owner (not through a work group) of:
- A role (bundle),
- An application,
- A work item (i.e. needs to perform work),
- A task result,
- Is a requester of any open work item,
- Is a secondary owner of any application,
- Is the remediator of any application,
- Is the mitigator of any policy violation or certification decision,
- Is being certified as part of any unfinished, non-continuous identity certification (and the option Do not delete identities being certified is ticked on the task)
