- Products & services Products & services
- Resources ResourcesLearning
- Learning
- Identity University Get technical training to ensure a successful implementation
- SailPoint professional certifications & credentials Advance your career or validate your identity security knowledge
- SailPoint recertification program Get recertified by demonstrating ongoing learning
- Training onboarding guide Make of the most of training with our step-by-step guide
- Training FAQs Find answers to common training questions
- Community Community
- Compass
- :
- Discuss
- :
- Community Wiki
- :
- IdentityIQ Wiki
- :
- Understanding identity refresh options
- Article History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Content to Moderator
Understanding identity refresh options
Understanding identity refresh options
- Overview
- Different types of identity refresh task execution
- Identity refresh task options in the UI
- Optional filter string to constrain the identities refreshed
- Optional list of group or population names to constrain the identities refreshed
- Refresh identities whose last refresh date is before this date
- Refresh identities whose last refresh date is at least this number of hours ago
- Refresh identities whose last refresh date is within this number of hours
- Include modified identities in the refresh window
- Refresh only identities marked as needing refresh during aggregation
- Do not reset the needing refresh marker after refresh
- Exclude identities marked inactive
- Refresh all application account attributes
- Refresh identity attributes
- Refresh identity entitlements for all links
- Refresh manager status
- Refresh assigned, detected roles, and promote additional entitlements
- Provision assignments
- Disable deprovisioning of deassigned roles
- Refresh role metadata for each identity
- Enable manual account selection
- Synchronize attributes
- Refresh the identity risk scorecards
- Maintain identity histories
- Process events
- Refresh logical application links
- Promote managed attributes
- Number of refresh threads
Overview
The Identity Refresh task of IdentityIQ is a critical component of any IdentityIQ installation. Identity Refresh tasks are used to update Identity attribute details, synchronize attributes to downstream systems, evaluate workflow triggers, evaluate policies and a literally over a dozen other operations for the system. Configuring a set of Identity Refresh tasks for an installation is an important technical task that requires understanding of all of the options available and the specific functions and performance impacts they have. This document uses the abbreviation "IDR" and "IDRT" for "Identity Refresh" and "Identity Refresh Tasks", respectively.
Different types of identity refresh task execution
An "Identity Refresh" is a batch software process that evaluates one or more Identity records in IdentityIQ. The default behavior of an Identity Refresh is to process all "non-workgroup" Identity objects defined in an IdentityIQ installation. It is common to specify a Filter or assign a Population to an IDRT that reduces then set of Identity records that are processed by the IDRT. An example of using a Filter or Population with an IDRT is to periodically re-evaluate workflow triggers (Identity Triggers) for only the "Active" employees to process any mid-day departures or terminations that occur and require the launching of a Leaver workflow.
By default IDR Tasks execute in a single-threaded fashion. In this configuration a single thread of execution runs on one of the Task Scheduler servers in an IdentityIQ installation, processing all of the Identity objects defined on the installation. Because each Identity is processed in relative isolation, separate from all of the other Identity objects being processed, the IDRT lends itself to benefit significantly from parallelization. Applying some kind of concurrency greatly increases the throughput and greatly decreases the "wall clock" time required to complete the task. All but the smallest IdentityIQ installations leverage some kind of concurrency configuration to minimize the amount of time an IRDT spends in execution.
Since the IdentityIQ 6.2 release IdentityIQ has made available two forms of concurrency or parallelization for IDR Tasks. One option is "Multi-threaded Identity Refresh" and the other option is "Partitioned Identity Refresh". The two options are mutually exclusive; either partitioned IDR is used or multi-threaded IDR is used but not both. Multi-threaded IDR is the older option, it has been in the IdentityIQ product since the 5.2 release, where all of the concurrent threads of IDR processing are executed from the single Task Scheduler server that executes the Identity Refresh process. Partitioned IDR is the newer option, added in 6.2, where the IDR task is divided into a number of partitions that are submitted as Request objects to the back-end database. The partitions are then adopted by the Request Scheduler modules of the Request Scheudler hosts in the IdentityIQ installtion. For more details on configuring partitioned IDR tasks see the following KB articles: Background Processing in IdentityIQ: The TaskScheduler and RequestScheduler and Partitioning Best Practices.
A common task used during development and testing is running an IDRT against a single test Identity or small set of test Identity objects. This is usually done to test Policy objects or test logic in Identity trigger rules, or test Identity Attribute promotion rule logic or attribute synchronization behavior. In this type of IDRT the task is restricted to a single Identity with a filter like name == "target.identityName" where the task is restricted to cover only one Identity. See the Filters section below for more details.
Identity refresh task options in the UI
As of the 6.4 release of IdentityIQ there are 36 options available in the user interface for configuration. These options control which Identity objects are processed during the refresh and turn on and off different behaviors of the software during the refresh. The following screen capture illustrates the options available in the user interface of the 7.0p1 edition of IdentityIQ. Each option is explained in-depth in the sections that follow, in approximately the order they are presented in the user interface. Click on the diagram for a zoomed in presentation.
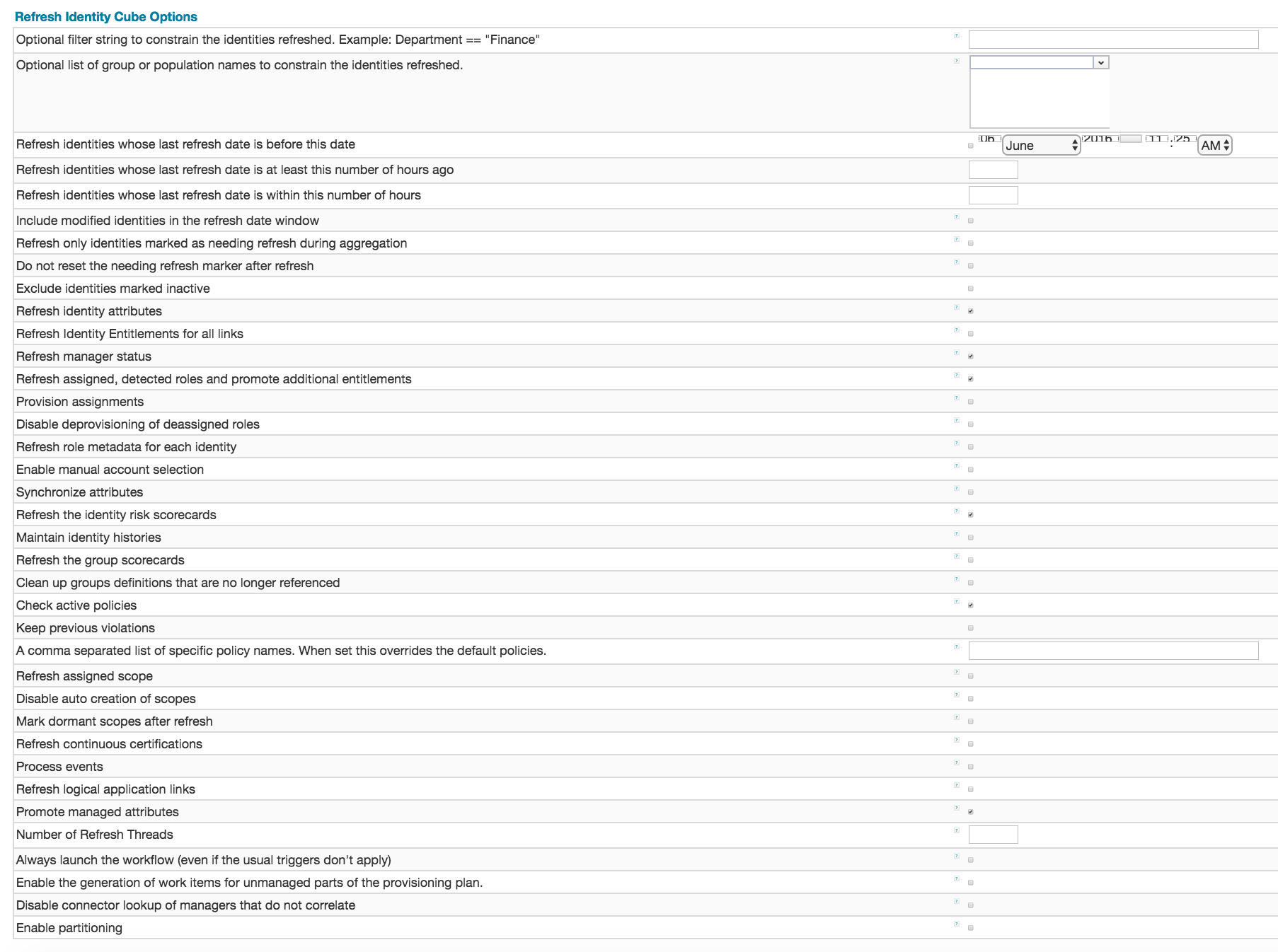
Optional filter string to constrain the identities refreshed
This text box provides a Filter to limit the Identity objects that are processed by the refresh. The syntax is expressed in SailPoint filter syntax. The most common use of this configuration item is to specify a set of Identity names or identity object properties to include in the refresh. When specified, only Identity objects that explicitly match this filter are included in the Identity refresh processing.
The following table provides commonly used examples for this field.
| Example Configuration | Description |
|---|---|
| name == "john.doe" | Apply the Identity Refresh operation only to the cube who's name matches the string "john.doe" |
| name.startsWith("100") | Apply the Identity Refresh operation only to the cubes whose names start with the string "100" |
| links.application.name == "Active Directory" | Apply the Identity Refresh operation only to cubes who have an account on the "Active Directory" application |
| inactive == false | Apply the Identity Refresh operation only to the cubes who have an "Active" identity status. |
More examples of Filter syntax can be found in the following KB article: Filters and Filter Strings.pdf.
Optional list of group or population names to constrain the identities refreshed
This drop-down allows you to specify a pre-configured group or population of users to include in the identity refresh task. Possible values for this field can be seen in the user interface under the Define -> Groups menu of the user interface.
Refresh identities whose last refresh date is before this date
This option instructs the identity refresh task to only process Identity cubes who's "lastRefresh" property is earlier than the specified date. This is useful for a one-time update of Identity objects that have been relatively untouched or dormant for long periods of time. Because this is a statically configured date in the task definition this option is of little use to regularly scheduled identity refresh tasks unless steps are taken to update the date value in the Task Definition for the refresh task.
Refresh identities whose last refresh date is at least this number of hours ago
This option includes Identity objects whose "lastRefresh" property is older than a specified number of hours ago. This is useful for a "daily sweep up" or "weekly sweep up" refresh task that processes Identity type objects that are not processed by other tasks.
Refresh identities whose last refresh date is within this number of hours
This option includes Identity objects whose "lastRefresh" property is a very recent time stamp. This option is used to re-process Identity objects that have had a changed in a very recent time frame. This can be used to run an operation against the cubes that have had activity in a recent number of hours. Because the identity refresh operation itself updates the "lastRefresh" property of an Identity object care must be taken to avoid a "snowballing effect" with this option; it is possible for daily or hourly tasks scheduled with this option to eventually grow in scale or scope to include all cubes.
Include modified identities in the refresh window
This option causes the identity refresh operation to include Identity objects with their "modified" time stamp property within the last number of hours specified in the previous option's hour window. This differs from the previous option in that it examines the "modified" time stamp and not the "lastRefresh" time stamp.
Refresh only identities marked as needing refresh during aggregation
Added in IdentityIQ 7.0, this option causes the identity refresh option to only include Identities who have been marked as needing refresh during a recent aggregation. This would be the result of disabling optimized aggregations, being a newly aggregated link, or an existing link that had changes during an optimized aggregation. This can be used to speed up the Identity refresh by only working on Identities that have changed since the last time we ran this task.
Do not reset the needing refresh marker after refresh
This option relates to the previous option and was also added in IdentityIQ 7.0. Without this checked, the refresh task will clear out the "needing refresh" flag on the Identity. This would cause a sequence of refreshes using the "Refresh only identities marked as needing refresh during aggregation" option to not cover all the desired Identities, since all but the first would see that no Identities need to be refreshed.
When an installation has multiple refresh tasks that will be executed for the same population with the desire to use the "Refresh only identities marked as needing refresh during aggregation" option, all but the last refresh in the sequence should use this option.
Exclude identities marked inactive
This option causes the identity refresh operation to not include Identity objects whose "inactive" property is set to true. This is useful for focusing a refresh operation on only Identity cubes who are considered active in HR (or active by whatever policy drives the "inactive" property of IdentityIQ).
Refresh all application account attributes
This option causes IdentityIQ to re-aggregate all of the Link objects correlated to Identity cubes being processed by the refresh. This effectively causes every account/link to call out to the remote system, gather a new ResourceObject, and then re-aggregate that account/link into IdentityIQ. This option should rarely be used based on its functional and performance implications. Only installations with all direct connectors (i.e. no delimited files or JDBC applications with out "getObject" SQLs configured) should consider using this option. If this option is enabled in an Identity Refresh task it is usually an indication of an error in the configuration; use of this option should be explicitly noted and explained in the description of the refresh task for tasks that chose to use this option.
Refresh identity attributes
This option causes the identity refresh task to re-evaluate all of the extended attributes of the Identity objects. This means IdentityIQ will re-evaluate mappings and attribute mapping rules for each Identity object covered in the refresh. Identity attributes are updated by default during account aggregations so this option is not always necessary if direct mapping is used for all Identity attributes. This option can have performance impacts if slow or complex attribute promotion bean shell code is in place on the installation.
Refresh identity entitlements for all links
This option iterates through all account/Link objects correlated to an Identity and detects the entitlements found on those acocunt/Link objects to the Identity cube. It is a more recent option (relative to the 6.x release line); it came along when the product introduced the spt_identity_entitlement table. Architects can think of this table as the master reconciliation of desired state vs. current state. Prior to the presence of this table IdentityIQ did not have a way to track desired state on entitlement objects. Before this table the product could report that an identity was missing some entitlements that were required by one of their assigned roles, but it could not tell the user that the identity was missing an entitlement that had been previously provisioned through LCM, or that the identity has an entitlement it gained outside of IdentityIQ processes (native change). The table is maintained normally through aggregation and provisioning activity this option causes the refresh to “true up” the table to be current at as of the time.
Refresh manager status
This option causes IdentityIQ to evaluate whether a particular Identity cube is a manager. It is necessary for manager correlation to happen correctly. It is only necessary to run after authoritative (HR) sources, or applications that drive manager attributes, have been re-aggregated. It examines the manager correlation rule for an Identity and correlates the manager's Identity cube to the manager reference on an Identity.
Refresh assigned, detected roles, and promote additional entitlements
This option causes IdentityIQ to do several operations that can not be atomically separated. It causes IdentityIQ to reevaluate the assigned roles for an Identity cube. This means IdentityIQ will process all of the assignment rule logic for all Business Roles that have automatic assignment logic defined. This option causes IdentityIQ to reevaluate the detected IT Roles on the Identity cubes processed by the refresh task. This means comparing the profiles defined on IT Roles for detection against the entitlements found on the accounts/Links correlated to the Identity cube. This re-processes what IT roles appear as detected for the Identity cube. Entitlements found on the Identity's accounts/Links are also promoted to the Identity cube during this process.
This option's primary function is to detect roles based on the entitlements that exist on an Identity’s application accounts/Links and automatically assign roles to the Identity that match the assignment rules. The promote entitlements bit refers to the fact that this option also creates EntitlementGroup objects on the cube. This process is required before generating certifications to ensure the certification contains accurate data. For example, if you aggregate a new entitlement on an account and then certify the identity before running a refresh with entitlement correlation enabled, then you will not see the entitlement in the cert. An installation has to run a refresh with this option to populate the EntitlementGroup objects on the identity cube. Architects can think of this process as a sieve, where the role model is the sieve. Roles are "caught" first by the sieve and if there is no role model, everything falls through and becomes an EntitlementGroup object on the cube. The EntitlementGroup objects drive the “Additional Entitlements” section you see in certifications.
For installations with large numbers of Roles (Bundles) defined this option can have significant performance impacts that can be mitigated with multi-threaded refreshing or partitioned refreshes.
Provision assignments
This option causes IdentityIQ to produce and execution Provisioning Plans for all entitlements that are assigned to an Identity cube but are missing in the accounts correlated to the cube. This option is necessary for direct connectors to automate provisioning for automatically assigned business roles. For connectors that are indirect and use manual work items this option must be used in conjunction with the "Enable the generation of work items for unmanaged parts of the provisioning plan." option to produce the manual work items for the indirect connectors.
Disable deprovisioning of deassigned roles
This option causes the identity refresh task to not remove Business Roles that were previously assigned to an Identity cube by auto-assignment logic. The default behavior of IdentityIQ to automatically remove Business Roles that were automatically assigned by assignment rules that no longer match due to a change in the Identity's properties after subsequent refreshes. This is useful if your installation does not want IdentityIQ to automatically revoke access assigned from roles; this is commonly the case for installations that use IdentityIQ for birthright access.
Refresh role metadata for each identity
This option examines what components of an assigned role (Business Role) are present on an identity's account/link objects. This operation expands the entitlements required by the roles assigned to the identity cube and compares them to what entitlements are present on the identity's accounts/links. Matches are identified and places where the role model calls for an entitlement but the identity is missing this entitlement are also identified. This is a key component of calculating role statistics.
Enable manual account selection
This option exists to support provisioning in situations where multiple accounts/links are correlated to a single Identity for a given application. In these circumstances it can be ambiguous which account should receive entitlements when a role is assigned to an identity cube. Checking this box causes IdentityIQ to prompt a user via a work item to specify which account should receive the entitlements. IdentityIQ's default behavior is to perform no provisioning in circumstances where this ambiguity exists and this option is not selected.
Installations with auto-assignment logic and multiple accounts correlated to cubes on role-covered applications (e.g. Active Directory is commonly found in this circumstance) should consider using this option.
Synchronize attributes
This option is used to turn on attribute synchronization from IdentityIQ to applications that are configured as targets for identity attribute synchronization. This option causes IdentityIQ to provision out identity attributes that have target mappings. This causes IdentityIQ to evaluate attribute target mapping rules and if there are any differences between the value on the target application's link correlated to the Identity create a provisioning plan for that target application's connector.
Refresh the identity risk scorecards
This option causes IdentityIQ to reevaluate the risk scores for the identity cubes covered in the refresh task. This option should only be checked for installations which are using risk scores as part of their access review configuration strategy.
Maintain identity histories
This option causes IdentityIQ to create an IdentitySnapshot record for all identity cubes covered by the refresh. It should normally not be selected for frequently run/executed/scheduled refresh tasks.
This option is known to cause performance problems on installations where this option is selected for daily execution. SailPoint recommends only weekly or monthly use of IdentitySnapshot objects when used at all.
Process events
This option causes IdentityIQ to process the "IdentityTriggers" against the Identity objects processed during the refresh task. It effectively turns on LCM workflow triggering for the identity refresh.
This option can have performance implications if there are several hundred workflow triggers defined on the system or if individual workflow triggers require significant amounts of time to process.
Refresh logical application links
This option causes IdentityIQ to reevaluate whether the identity object has accounts/Links on logical applications. It causes IdentityIQ to evaluate each Logical application defined in the system and compare the requirements for those logical applications against the links and entitlements found on the identity cube. This effectively re-aggregates all of the logical application accounts for the identity.
For performance reasons this option is the preferred option for re-aggregating Logical application accounts for all identities. Avoid using account aggregation tasks for logical application account aggregations; use this option instead. There are recommended best practices for configuring logical application refreshes including:
- Place logical application re-aggregations in their own Identity Refresh task.
- Perform only this option in the dedicated refresh task.
- Make extensive utilization of multi-threading or partitioning in this task.
- Configure the filters on this task to include only identity cubes that have links on known logical application names
Promote managed attributes
This option causes IdentityIQ to examine the set of entitlements that exist on all links for an application and create ManagedAttribute (entitlement catalog) entries for each entitlement detected on accounts aggregated from the application.
Number of refresh threads
This text box specifies the number of independent threads that should be used during the processing of the refresh task. This applies only to single-host identity refresh tasks that are not partitioned. Without partitioning and with nothing specified in this text box IdentityIQ will default to a single-thread executing the Identity refresh task.
When set to a value larger than one the set of identity objects is split evenly among the threads to carry out execution in parallel. This is an advised and recommended approach to achieving the best performance and scale out of an Identity refresh task. Finding the optimum number of threads to configure a specific refresh task for is specific to each installation. The number of processor cores, database connections available, and types of operations configured for the refresh task drives the number of threads that can be safely configured.
This option from Identity 5.2 is generally not used in favor of the newer "Enable Partitioning" feature that was added in 6.2. Both options are fully supported. Installations preferring to keep all Identity Refresh activities isolated to a singleton Task Scheduler host might consider this option. Those installations are advised to try to keep the number of refresh threads specified lower than the "10 x [the number of cores on the Task Scheduler host]". Care and testing should be taken to prevent degraded overall performance from over-committing the CPU resources of the Task Scheduler host that adopts the IDRT. This option does not generally cause saturation (Back-End Database Server Saturation), and has the benefits of keeping all of the Log4j logging messages configured for the IDRT in a singe server's log file.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
It looks like a significant portion of this document was lost. The last paragraph introduces a "section" of XML-only options, but then just suddenly stops. Please try to recover the complete version of this document, or point me to another whitepaper that explains the tedious details of these refresh options.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
The document covers most of the topics in detail. thanks for that.
Please cover the below option in detail
Always Launch workflow(even if the usual trigger don't apply)
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
It would be nice to have:
a) Detailed documentation like this accessible directly from the corresponding screen in the UI (this is just one example). In general, dedicated documentation like this on various topics is often very hard to locate, and there seems to be no way to know what even exists.
b) A system table of some sort that contains the cross reference between the option label in the UI and the corresponding XML attribute in the underlying artifact (as a general practice) - this would enable an easier development of alternative UI's that could be used to quickly analyze system configuration (and comparison between instances of a task type)
ie: "filterNeedsRefresh" | "Refresh only identities marked as needing refresh during aggregation"
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
Can we update this with an order of operations? When does process events run in comparison to other options?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
"Can we update this with an order of operations? When does process events run in comparison to other options?"
I agree that would be awesome
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
"Can we update this with an order of operations? When does process events run in comparison to other options?"
I would like this, too! @rose_cobb, I see you are the last person who updated this. Is this something that would be possible?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
@thasheider, @benjamin_moya_synetis, @walker_pa ,
Although there is not an option directly on the task to enable an order of operations, you can easily implement that by creating multiple refresh tasks that only perform a single operation and then running/scheduling them via a Sequential Task. A Sequential Task will execute each task in the order that they are entered, so that would function as an order of operations. You can even configure the Sequential task to cease execution if one of the executing tasks encounters an error. It is actually a best practice to separate the operations on the Refresh Task instead of running a single refresh with all of the options enabled.
I would love to hear your use cases on why you'd like to utilize an order of operations on the refresh task though. I've never had that need since I usually will separate out the refresh tasks for performance reasons.
Alternatively, you could also set a rule on the refresh task that will perform whatever actions are necessary. You could even launch a workflow that would have several steps that refresh the identity, but only with specific options enabled. Depending on your use case, you could even update the "Identity Refresh" workflow so that it performs several refreshes but with specific options enabled.
Finally, you can always submit a feature request on the Ideas portal, but that would take some time for it to go from an idea to a backlog item and then finally implemented into the product. I'm sure you can find a suitable solution from the options I detailed and that would be much faster to implement.
Cheers!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
@Eric_Mendes_CISSP Thanks for the reply. My interpretation of the question posed by @thasheider was that they wanted the documentation to reflect the order in which each task runs, but I don't want to speak for them. Personally, I don't need to have each subtask run in a specific order, but I like to have a detailed understanding of how things work.
If the task runs how I'd imagine it runs, there are probably if statements which evaluate which box is checked, then calls a method to do the actual subtasks within the Identity Refresh in a sequential manner. Having the sequential order documented would be helpful to understanding if there are any implications for running all the subtasks together versus what you've suggested. For me, it's just about understanding the task at a more granular level.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
@Eric_Mendes_CISS @walker_pa Thanks for replying to this both of you. Walker is correct, if I have an Identity Refresh task that has promote managed attributes, process events and Refresh assigned, detected roles and promote additional entitlements checked, which one is ran first? I assume it's some kind of switch/if statements from top down but I'd love to know for sure.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
Same here. @rose_cobb Would like more information on order of execution and an explanation of the "Always Launch Workflow" as well as a typical use case for it.
