- Products & services Products & services
- Resources ResourcesLearning
- Learning
- Identity University Get technical training to ensure a successful implementation
- SailPoint professional certifications & credentials Advance your career or validate your identity security knowledge
- SailPoint recertification program Get recertified by demonstrating ongoing learning
- Training onboarding guide Make of the most of training with our step-by-step guide
- Training FAQs Find answers to common training questions
- Community Community
- Compass
- :
- Discuss
- :
- Community Wiki
- :
- IdentityIQ Wiki
- :
- Aggregations have several rule hooks, when are they used in the aggregation process?
- Article History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Content to Moderator
Aggregations have several rule hooks, when are they used in the aggregation process?
Aggregations have several rule hooks, when are they used in the aggregation process?
Post Date: May 3, 2011
Posted By: Trey Kirk
During aggregation, there are several places where rules are executed to provide implementers some control on how data is being aggregated. Each rule hook has a specific purpose and certain requirements can be met at each point. This article explains that process and points out the more common requirements each rule hook can address.
Aggregation Start: Aggregation begins when the aggregation task is executed.
Pre-iterate Rule: The Delimited File Connector supports the use of a Pre-iterate rule. It is currently the only connector that supports a pre-iterate rule (and post-iterate). However, this may change in a future release. The purpose of the pre-iterate rule is to allow any expensive one-time operations to take place that will enable or improve the overall performance of the aggregation. Typically, this may be any of the following:
- Relocating the file from a network mount to a local mount
- Validating the file contents
- Performing advanced file manipulations resulting in a meta-view of the file data (i.e. merging two CSV source files into one stream)
The inputs of a Pre-Iterate rule are:
<Inputs>
<Argument name='context'>
<Description>
A SailPointContext object used if its necessary
to query objects from the database.
</Description>
</Argument>
<Argument name='application'>
<Description>
Application being iterated.
</Description>
</Argument>
<Argument name='schema'>
<Description>
Schema representing the data being iterated
</Description>
</Argument>
<Argument name='stats'>
<Description>
A map passed by the connector of the stats for the file about to be iterated.
Contains keys:
fileName : (String) filename of the file about to be processed
absolutePath : (String) absolute filename
length : (Long) length in bytes
lastModified : (Long) last time the file was updated Java GMT
</Description>
</Argument>
<Argument name='log'>
<Description>
log for debugging
</Description>
</Argument>
</Inputs>
The return of a pre-iterate rule is an InputStream. When using the pre-iterate rule to validate an input file, one should throw a GeneralException when validation fails. Returning a null InputStream will not interrupt the aggregation and the original InputStream will continue to be used.
Iterate objects: The desired objects are iterated and the following rules are run per account and/or per line of data
Build Map: For delimited and JDBC connectors, a Map of data is fetched for each row of data. A build map rule hook is provided to allow one to modify the row of data as needed. Typical requirements are:
- Determine any derived values
- Exclusion of data lines
The inputs of a Build Map Rule are:
<Inputs>
<Argument name='application'>
<Description>
The application whose data file is being processed.
</Description>
</Argument>
<Argument name='schema'>
<Description>
The Schema currently in use.
</Description>
</Argument>
<Argument name='state'>
<Description>
A Map containing state information.
</Description>
</Argument>
<Argument name='record'>
<Description>
A List of data tokens parsed from the current line of the data file.
</Description>
</Argument>
<Argument name='cols'>
<Description>
A List of the columns to use.
</Description>
</Argument>
</Inputs>
The return of a Build Map Rule is a Map with keys named as per the schema attributes.
Merge Maps: For Delimited and JDBC connectors, multiple rows of data may need to be merged to represent the full view of a given Map of data. In the Merge Maps rule, for each row of data parsed, a Map is passed in and merged into a second, on-going Map. Overriding the default merge logic is uncommon, but has been done. One usually does this when merging values is not as straightforward as what the default merge for the Delimited and JDBC connectors do. The inputs of a Merge Maps rule are:
<Inputs>
<Argument name='application'>
<Description>
The application associated with the Connector calling the rule.
</Description>
</Argument>
<Argument name='schema'>
<Description>
The Schema from the application.
</Description>
</Argument>
<Argument name='current'>
<Description>
The current Map object that needs merging.
</Description>
</Argument>
<Argument name='newObject'>
<Description>
The new Map object that needs merging.
</Description>
</Argument>
<Argument name='mergeAttrs'>
<Description>
A List of the attributes to merge.
</Description>
</Argument>
</Inputs>
The return of the Merge Maps rule should be the newly merged Map object.
Customization: Once all data merging has been done (for Delimited and JDBC applications, other connectors will offer this hook as the first oppurtunity to modify aggregating data), a ResourceObject is built. Typical use cases for the Customization Rule are:
- Account exclusion: when a condition is met indicating a given account should not be aggregated into IIQ, one simply needs to return a null ResourceObject
- One may also use the Customization rule to determine derived values or otherwise modify account attribute data
Inputs are:
<Inputs>
<Argument name='object'>
<Description>
The ResourceObject built by the connector.
</Description>
</Argument>
<Argument name='application'>
<Description>
Application that references the connector.
</Description>
</Argument>
<Argument name='connector'>
<Description>
The connector object.
</Description>
</Argument>
</Inputs>
The return of this rule is a ResourceObject.
Identity Correlation: Correlation is the next step during aggregation. The ResourceObject is next passed into a Correlation scheme to identify an owning Identity object. Should a correlation configuration be provided in the Application's configuration, that correlation logic is used. Otherwise, the older method of using a Correlation Rule is used. This documents the specifics of that rule.
The inputs are:
<Inputs>
<Argument name='environment' type='Map'>
<Description>
Arguments passed to the aggregation task.
</Description>
</Argument>
<Argument name='application'>
<Description>
Application being aggregated.
</Description>
</Argument>
<Argument name='account'>
<Description>
A sailpoint.object.ResourceObject returned from the
collector.
</Description>
</Argument>
<Argument name='link'>
<Description>
Existing link to this account.
</Description>
</Argument>
</Inputs>
A Map is the intended return with well-known key names defined. That Map may contain the following sets of data:
- A key / value pair to be used to find the owning Identity: If an attribute on the inputted ResourceObject is known to provide a descrete search for the Identity that should be linked to the ResourceObject, one may return the name of that attribute mapped as 'identityAttributeName' and the value of that attribute mapped as 'identityAttributeValue'. IIQ will then perform a search using that criteria to find the correlated Identity.
- The owning Identity object: The rule may include its own logic to search for an owning Identity. When this is used, it may return an Identity object for the owning Identity mapped as 'identity'.
- The name of the owning Identity: The rule may again include its own logic to search for an owning Identity. In this instance, it may instead return a String value declaring the name of the associated Identity. This String should be mapped as 'identityName'
Creation: When correlation does not find an Identity, one is created automatically. It is a rule that every account aggregated into IdentityIQ must be linked to exactly one Identity. This is true even if the inbound account is the only account linked to the Identity. In that situation, we'd often recognize that as an uncorrelated Identity. When creating these Identities for accounts that did not find a correlated Identity, a Creation Rule hook is provided. The typial requirements for a creation rule are:
- Ensuring a common naming convention for new Identities
- Defining derived Identity attribute values (One should consider using Identity Mappings for this use case instead)
- Assigning capabilities based on attributes of the inbound account
The inputs of the Creation Rule are:
<Inputs>
<Argument name='environment' type='Map'>
<Description>
Arguments passed to the aggregation task.
</Description>
</Argument>
<Argument name='application'>
<Description>
Application being aggregated.
</Description>
</Argument>
<Argument name='account' type='ResourceObject' required='true'>
<Description>
The resource account for the identity being created.
</Description>
</Argument>
<Argument name='identity' type='Identity' required='true'>
<Description>
The identity that is being created.
</Description>
</Argument>
</Inputs>
There is no return expected from this rule. All changes must be done to the inbound Identity object. Nulling out the Identity object will interrupt the aggregation and is thus not an effective method to exclude accounts.
Iteration continues to the next account: At this point, iteration will continue until the last account has been processed.
Post Iteration: A post iteration rule hook is provided for delimited files as a one-time rule hook for any post aggregation activities. Typical requirements for this rule may include cleaning any temporary source files created as part of the pre-iterate rule. Inputs of the post-iterate rule are:
<Inputs>
<Argument name='application'>
<Description>
Application being iterated.
</Description>
</Argument>
<Argument name='schema'>
<Description>
Schema requested during iteration.
</Description>
</Argument>
<Argument name='stats'>
<Description>
A map of the stats for the current file that was just iterated.
Contains keys:
fileName : (String) filename of the file about to be processed
absolutePath : (String) absolute filename
length : (Long) length in bytes
lastModified : (Long) last time the file was updated Java GMT
columnNames : (List) column names that were used during the iteration
objectsIterated : (Long) total number of objects iterated during this run
</Description>
</Argument>
</Inputs>
No return is expected from this rule.
See the image below for a graphical representation of when each rule type launches during aggregation.
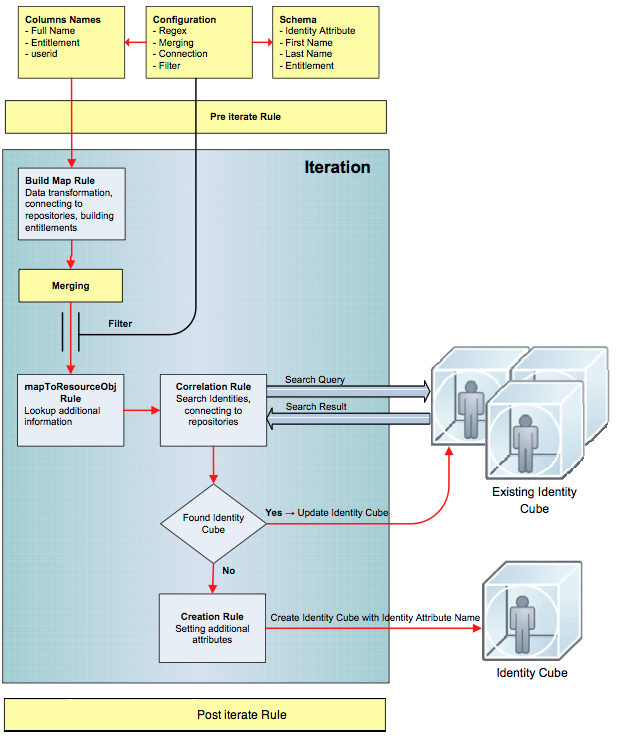
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
FYI - the Rules document has further information (including useful architecture guidance on performance): Rules in IdentityIQ.pdf
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
Is it best practice to update a "ResourceObject" attribute (like "password type") in the customization rule, and THEN the IdentityCube attribute (also "password type") at the correlation rule? Or should both the ResourceObject and the IdentityCube be customized first at the customization rule?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Content to Moderator
Rob Temple, this is a great question to post in the forums for a wider audience than just folks following this document.
